Explained variation
In statistics, explained variation or explained randomness measures the proportion to which a mathematical model accounts for the variation (= apparent randomness) of a given data set. Often, variation is quantified as variance; then, the more specific term explained variance can be used.
The complementary part of the total variation/randomness/variance is called unexplained or residual.
The simplified assumption of explained variance as equal to the square of the correlation coefficient has been criticized. "for most social scientists, is of doubtful meaning but great rhetorical value".[1][2]
Contents |
Definition
Explained variation is a relatively recent concept. The most authoritative source seems to be Kent (1983) who founded his definition on information theory.
Information gain by better modelling
Following Kent (1983), we use the Fraser information (Fraser 1965)
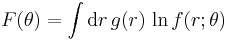
where 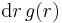 is the probability density of a random variable
is the probability density of a random variable 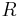 , and
, and 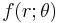 with
with 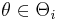 (
(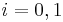 ) are two families of parametric models. Model family 0 is the simpler one, with a restricted parameter space
) are two families of parametric models. Model family 0 is the simpler one, with a restricted parameter space 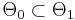 .
.
Parameters are determined by maximum likelihood estimation,
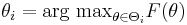 .
.
The information gain of model 1 over model 0 is written as
![\Gamma(\theta_1:\theta_0) = 2 [ F(\theta_1)-F(\theta_0) ]\,](/2012-wikipedia_en_all_nopic_01_2012/I/13f882d6059dd1cefdb68fcceb162385.png)
where a factor of 2 is included for convenience. Γ is always nonnegative; it measures the extent to which the best model of family 1 is better than the best model of family 0 in explaining g(r).
Information gain by a conditional model
Assume a two-dimensional random variable 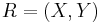 where X shall be considered as an explanatory variable, and Y as a dependent variable. Models of family 1 "explain" Y in terms of X,
where X shall be considered as an explanatory variable, and Y as a dependent variable. Models of family 1 "explain" Y in terms of X,
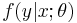 ,
,
whereas in family 0, X and Y are assumed to be independent. We define the randomness of Y by ![D(Y)=\exp[-2F(\theta_0)]](/2012-wikipedia_en_all_nopic_01_2012/I/c4681b187f6fa385a8d3eff6aa9a8974.png) , and the randomness of Y, given X, by
, and the randomness of Y, given X, by ![D(Y|X)=\exp[-2F(\theta_1)]](/2012-wikipedia_en_all_nopic_01_2012/I/b928a0c21b722fae851c39095b495050.png) . Then,
. Then,
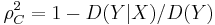
can be interpreted as proportion of the randomness which is explained by X.
Special cases and generalized usage
For special models, the above definition yields particularly appealing results. Regrettably, these simplified definitions of explained variance are used even in situations where the underlying assumptions do not hold.
Linear regression
The fraction of variance unexplained is an established concept in the context of linear regression. The usual definition of the coefficient of determination seems to be compatible with the fundamental definition of explained variance.
Correlation coefficient as measure of explained variance
Let X be a random vector, and Y a random variable that is modeled by a normal distribution with centre 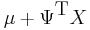 . In this case, the above-derived proportion of randomness
. In this case, the above-derived proportion of randomness 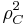 equals the squared correlation coefficient
equals the squared correlation coefficient 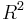 .
.
Note the strong model assumptions: the centre of the Y distribution must be a linear function of X, and for any given x, the Y distribution must be normal. In other situations, it is generally not justified to interpret as proportion of explained variance.
Explained variance in principal component analysis
"Explained variance" is routinely used in principal component analysis. The relation to the Fraser-Kent information gain remains to be clarified.
Criticism
As "explained variance" essentially equals the correlation coefficient , it shares all the disadvantages of the latter: it reflects not only the quality of the regression, but also the distribution of the independent (conditioning) variables.
In the words of one critic: "Thus gives the 'percentage of variance explained' by the regression, an expression that, for most social scientists, is of doubtful meaning but great rhetorical value. If this number is large, the regression gives a good fit, and there is little point in searching for additional variables. Other regression equations on different data sets are said to be less satisfactory or less powerful if their is lower. Nothing about supports these claims".[3] And, after constructing an example where is enhanced just by jointly considering data from two different populations: "'Explained variance' explains nothing" [4][5]
Notes
Further reading
- D A S Fraser (1965) "On Information in Statistics", Ann. Math. Statist., 36 (3), 890-896.
- C H Achen (1982) Interpreting and Using Regression, Beverly Hills: Sage.
- J T Kent (1983) "Information gain and a general measure of correlation", Biometrika, 70(1), 163-173. JSTOR 2335954
- C H Achen (1990) '"What Does "Explained Variance" Explain?: Reply", Political Analysis, 2(1),173-184. doi:10.1093/pan/2.1.173